WPS新推出的PIVOTBY函数,为动态数据统计提供了更优的方案。它被称为“透视表函数版”,既能像传统透视表那样完成数据分组汇总,又完美解决了透视表需要手动刷新的老问题——只要数据源有变动,PIVOTBY函数的计算结果会自动同步更新。这个特性让PIVOTBY函数在动态报表制作、数据看板搭建等场景中格外实用,无论是日常办公还是复杂数据分析,都能帮用户节省大量操作时间。
一、PIVOTBY函数核心解析
PIVOTBY函数的核心价值在于将数据按指定维度进行重组计算,简单来说,就是用函数代码替代了透视表的拖拽操作。它能自动完成数据分组、指标聚合、结果排序和条件筛选等一系列操作,是函数化的数据透视解决方案。
1.基础语法结构
函数的完整表达式为:=PIVOTBY(行维度区域,列维度区域,数值区域,计算方式,[其他可选参数…])
2.核心参数说明
该函数的参数体系中,有四个基础参数决定了统计结果的基本形态,掌握它们就能应对80%的统计需求:
- 行维度区域(首个参数):对应数据分组的行方向分类依据,相当于透视表中行标签的角色。既可以选择单一列数据(如“地区”),也能选取多列形成层级关系(如“地区+城市”)。
- 列维度区域(第二个参数):用于定义列方向的分类维度,类似透视表的列标签。如果只需要行方向的统计结果,此处可直接空置;若需按列分组,则填入对应的数据列范围。
- 数值区域(第三个参数):指定需要进行计算的数值所在列,对应透视表的值区域。支持同时选中多列数据(如“销量”和“销售额”),实现多指标并行统计。
- 计算方式(第四个参数):设定具体的统计逻辑,常用的包括求和(SUM)、计数(COUNT)、平均值(AVERAGE)等,也支持通过LAMBDA函数自定义计算规则。
这四个参数构成了PIVOTBY函数的基本框架,理解它们的作用逻辑,就能快速构建所需的统计模型。
二、PIVOTBY函数实战用法
1.基础维度统计(对应透视表基础功能)
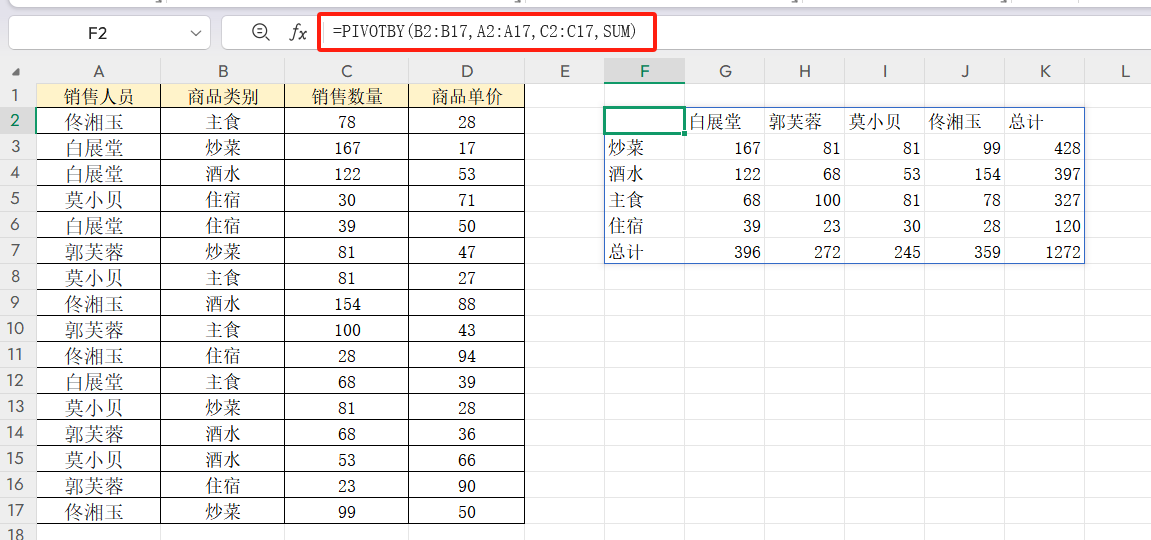
应用场景:按“商品类别”(行)统计“销售人员”(列)的销售数量总和。
函数公式:=PIVOTBY(B2:B17,A2:A17,C2:C17,SUM)
公式解析:
行维度参数:B列“商品类别”,作为统计的行维度
列维度参数:A列“销售人员”,作为统计的列维度
数值参数:C列“销售数量”,作为计算的数值来源
计算方式:使用SUM函数对订单数量进行求和运算。
2.多维组合统计(支持多字段并行分析)
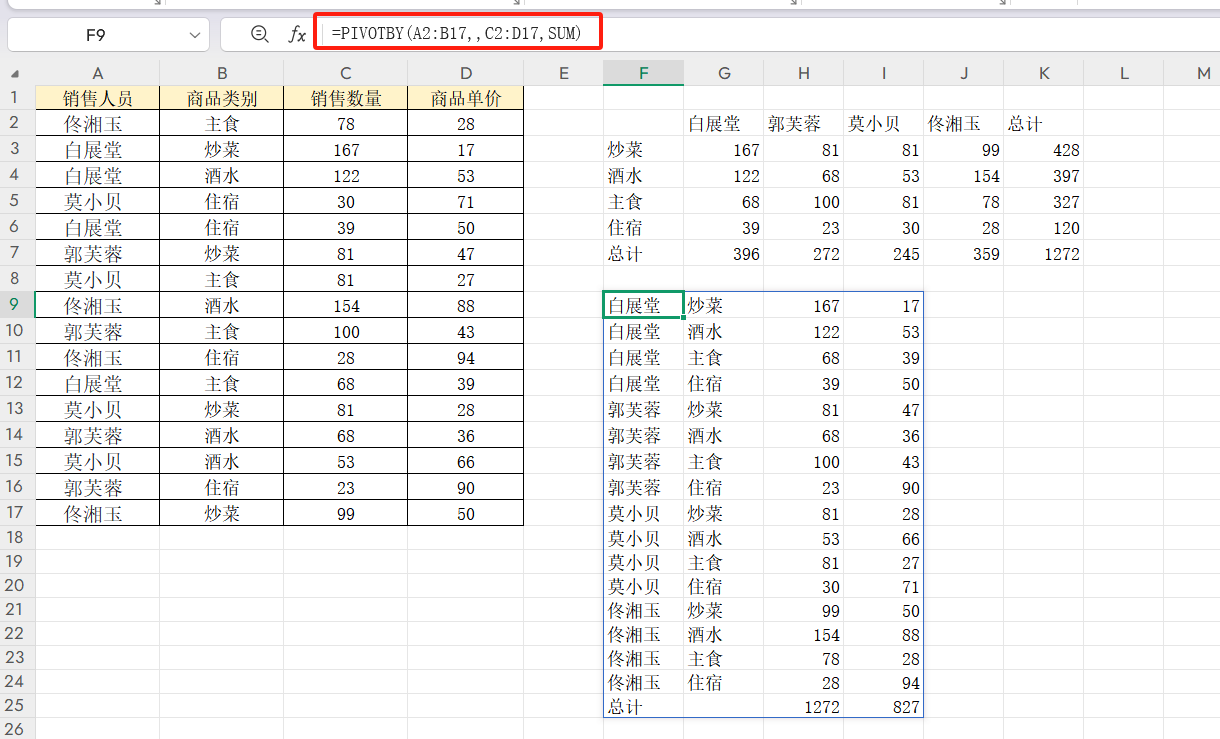
应用场景:
按“销售人员+商品类别”(多行字段)统计“数量+单价”(多值字段)总和。
公式:=PIVOTBY(A2:B17,,C2:D17,SUM)
解读:
第一个参数:A1:B10(两列行字段,实现“销售人员→商品类别”的层级分组)
第二个参数:留空(无需按列分组,仅展示行维度统计结果)
第三个参数:C2:D17(同时统计“数量”和“单价”两列数据)
如果需要处理非连续的数据列,可借助HSTACK函数进行整合(例如HSTACK(A1:A20,D1:D20)),将分散的列数据转换为连续区域后再传入参数。
结语
PIVOTBY函数的出现,为Excel动态数据统计提供了全新方案。它用函数化的逻辑重构了透视表的核心功能,不仅保留了分组汇总的灵活性,更通过自动更新特性解决了传统透视表的动态性难题。目前新版WPS表格中已支持该函数,对于需要频繁处理动态数据的用户来说,掌握它将大幅提升数据统计的效率和准确性。






