在数据统计工作中,如何精准计算总体标准差是一个常见难题。若直接使用常规统计方法,很容易因非数值数据的处理不当导致结果失真。而STDEVPA函数就成为了关键解决方案,它能将非数值数据转换为可计算形式,确保所有数据都参与运算。无论是面对文本字段的分析,还是逻辑值的处理,STDEVPA函数都能精准应对。今天这篇文章全面解析了STDEVPA函数用法,让复杂数据的离散程度分析获得可靠且精确的结果。
一、STDEVPA与STDEVP的数据处理方式
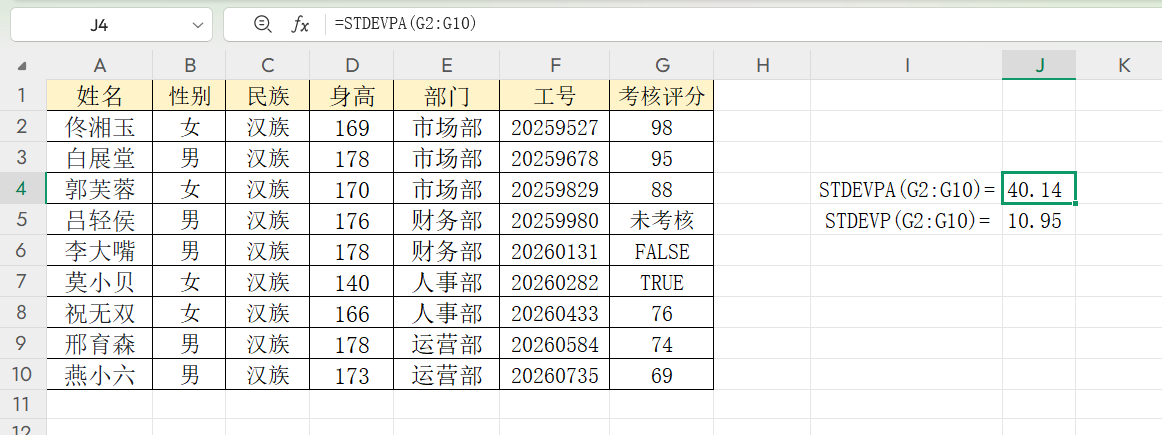
总体标准差计算的关键挑战在于非数值数据的处理逻辑。例如在员工绩效统计中,数据里可能既有“92”“78”这样的具体分数,也有文本标注,还有“TRUE”(代表达标)这类逻辑值。
- STDEVP函数的处理方式是仅保留数值数据,直接忽略文本和逻辑值。这种情况下,计算依据的是部分数据,结果无法反映整体情况,可能出现明显偏差。
- STDEVPA函数则采用统一转换规则:文本无论内容均视为0,TRUE转换为1,FALSE转换为0。所有数据都会参与计算,结果能真实体现总体的离散特征。
两者的适用场景也因此明确:纯数值数据可选择STDEVP以提高效率;当数据中存在文本或逻辑值时,必须使用STDEVPA才能保证结果的准确性。
二、STDEVPA函数的基础使用方法
(1)语法结构
函数的基本格式为“STDEVPA(value1,[value2],…)”。其中:
value1是必需参数,可输入数值、文本、逻辑值或单元格引用;
[value2]及后续参数为可选,最多可添加254个数据参数。
(2)数据处理规则
STDEVPA对不同类型数据的处理方式有明确规定:
数值:直接参与计算(如“85”“92.3”);
文本:包括具体描述(如“未完成”)和空格文本(如“”),均按0计算;
逻辑值:TRUE按1计算,FALSE按0计算;
空白单元格:不参与运算,直接忽略。
需要特别注意的是,空白单元格和文本是完全不同的概念。例如:A1单元格为空时,该单元格不参与计算;A2单元格输入“”(空格文本),则会被视为0纳入运算,两者对结果的影响有本质区别。
(3)操作步骤
若要计算A1到A50单元格区域的总体标准差,只需在目标单元格中输入“=STDEVPA(A1:A50)”,系统会自动按照规则转换区域内的非数值数据,并快速得出计算结果。
三、STDEVPA函数的实际应用场景
(1)人力资源管理:员工绩效波动分析
某企业有80名员工,其中8人标记“待入职”(文本)、6人标记“TRUE”(代表绩效优秀)。使用STDEVPA计算总体标准差后:
若结果为10分(平均分80分),说明多数员工绩效在70-90分之间,整体波动较小;
若标准差达到20分,则表明绩效差距较大,需要重点关注低分和特殊标记的员工群体。
(2)教育统计:含特殊标记的成绩分析
在一个50人的班级中,有4人因“缺考”标记为文本,2人因“作弊”标记为文本。使用STDEVPA计算时,这些特殊标记会按0参与运算,结果能真实反映全班成绩的离散程度。如果误用STDEVP函数,会忽略这些数据,可能掩盖实际存在的成绩分化问题。
(3)质量检测与市场调研数据处理
质量检测中,“不合格”“返工”等文本标记可通过STDEVPA按0纳入计算,避免因忽略不良品数据导致对产品质量的误判;
市场调研时,“未反馈”等文本和“推荐”等逻辑值能被合理转换,确保用户反馈数据的完整性,使分析结果更可靠。
四、使用注意事项与高效技巧
1.常见误区提醒
函数无法识别文本的实际含义:无论文本是“优秀”还是“差”,都会被统一视为0。若需体现文本的实际意义,需提前用IF函数转换(例如“=IF(A1=”优秀”,95,A1)”);
明确区分空白单元格与文本:空白单元格不参与计算,而文本(包括空格文本)会按0计算,两者对结果的影响不同;
仅适用于总体数据:如果处理的是样本数据(如从1000个数据中抽取50个),应改用STDEVA函数。
2.函数联用技巧
与IF函数组合:可自定义非数值数据的转换规则。例如“=STDEVPA(IF(A1:A80=”未考核”,60,A1:A80))”,将“未考核”按60分计算(输入后需按Ctrl+Shift+Enter确认数组公式);
与AVERAGEPA函数搭配:STDEVPA反映数据的离散程度,AVERAGEPA反映数据的集中趋势,两者结合能更全面地描述数据特征。
结语
STDEVPA函数的核心优势在于为包含文本、逻辑值的复杂总体数据提供了完整的统计解决方案。在使用时,需先明确数据是否包含非数值信息——只要存在非数值标记,就应优先选择STDEVPA。掌握这一工具,能让复杂数据的离散分析更精准、高效,为决策提供更可靠的统计依据。






