很多新手在操作Excel经常被提取汉字难住,尤其是“一-龟”能代表所有汉字这一说法,更是让他们困惑不已。实际上,“一-龟”看似奇特的表达,是Excel在字符编码运用上的巧妙之处。接下来,我们就一同探寻“一-龟”的秘密,了解它为何能成为提取汉字的“利器”。
一、汉字提取的关键所在
在Excel里,若要从混合内容中提取汉字,常能见到这样的公式:=REGEXP(A2,”[一-龟]”)。这里的“一-龟”可不是随便凑出来的,它是能够准确匹配所有汉字的“密钥”。这背后的关键,得从Unicode编码讲起。
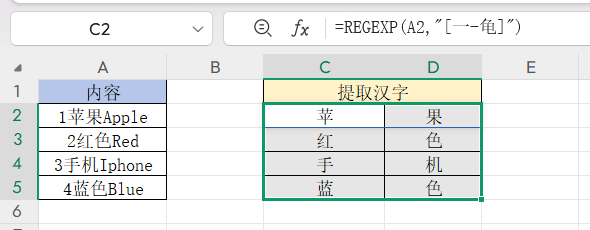
Unicode是一种在全球范围内通用的字符编码标准,它给每种语言里的每个字符都分配了独一无二的数字编码。在Unicode中,简体汉字的编码被限定在19968到40869这个区间,对应着20902个汉字。我们可以用Excel的UNICHAR函数来证实:输入=UNICHAR(19968),会得到“一”;输入=UNICHAR(40869),则会得到“龥”。这表明19968到40869编码所对应的汉字,其实是从“一”到“龥”的全部汉字。
二、生僻字的简化及实际需求
既然汉字的实际范围是“一-龥”,那在实际应用中为什么常用“一-龟”呢?原因很简单:“龥”以及它前后的一些汉字,像“龠”“龡”等,都非常生僻,在日常生活中几乎用不到,而且书写和输入也很麻烦。而“龟”是这个编码区间里倒数第7个汉字,不仅常用,输入起来也很容易。用“龟”代替“龥”作为范围的终点,既不会影响对所有常用汉字的涵盖,又能让公式的书写更加简便。所以,=REGEXP(A2,”[一-龟]”)和=REGEXP(A2,”[一-龥]”)这两个公式的效果是一样的,前者只是更符合实际使用的简化表达。
结语
Unicode汉字编码区间“一-龥”在Excel中的实用简化形式,便是“一-龟”代表全部汉字的底层逻辑。理解这一原理,不仅有助于我们在正则提取汉字时更加得心应手,还能加深对Excel与字符编码体系关联性的认知。日后遇到Excel中的其他技巧,不妨从编码逻辑角度深入剖析,或许会解锁新的知识维度。






